






책소개
실전에 필요한 머신러닝 시스템 설계, 데이터 수집, 효과 검증 노하우
머신러닝 알고리즘처럼 다른 책에서도 많이 다루는 주제 대신, 이 책에서는 “실무에서는 어떻게 해야 하지?”라는 궁금증을 해결하는 데 집중한다. 1부에서는 머신러닝 프로젝트를 처음 시작하는 방법, 시스템 구성법, 학습용 데이터 수집, 효과 검증에 필요한 저자들의 노하우를 알려준다. 2부에서는 저자가 엄선한 세 가지 프로젝트를 따라 해보며 실무 감각을 키울 수 있도록 구성했다.
주요 내용
1부. 머신러닝 실무 노하우
- 머신러닝 프로젝트 처음 시작하기
- 머신러닝으로 할 수 있는 일
- 학습 결과 평가하기
- 기존 시스템에 머신러닝 통합하기
- 학습 데이터 수집하기
- 효과 검증하기
2부. 머신러닝 실무 프로젝트
- 프로젝트 1 : 영화 추천 시스템 만들기
- 프로젝트 2 : 킥스타터 분석하기
- 프로젝트 3 : 업리프트 모델링으로 마케팅 효율 높이기
저자소개

목차
1부. 머신러닝 실무 노하우
1장. 머신러닝 프로젝트 처음 시작하기
1.1 머신러닝은 어떻게 동작하는가
1.2 머신러닝 프로젝트의 과정
__1.2.1 문제 정의하기
__1.2.2 머신러닝을 사용하지 않는 방법 검토하기
__1.2.3 시스템 설계하기
__1.2.4 알고리즘 선택하기
__1.2.5 특징, 정답 데이터, 로그 설계하기
__1.2.6 데이터 전처리
__1.2.7 학습 및 파라미터 튜닝
__1.2.8 시스템에 통합하기
1.3 운영 시스템에서 발생하는 머신러닝 문제 대처 방법
__1.3.1 사람이 작성한 황금기준을 사용하여 예측 성능 모니터링
__1.3.2 예측 모델을 모듈화하여 알고리즘에 대한 A/B 테스트 수행
__1.3.3 모델 버전관리를 통한 자유로운 롤백
__1.3.4 데이터 처리 파이프라인 저장
__1.3.5 개발 시스템과 운영 시스템의 언어 및 프레임워크 일치
1.4 머신러닝 시스템을 성공적으로 운영하려면
1.5 정리
2장. 머신러닝으로 할 수 있는 일
2.1 머신러닝 알고리즘 선택 방법
2.2 분류
__2.2.1 퍼셉트론
__2.2.2 로지스틱 회귀
__2.2.3 서포트 벡터 머신
__2.2.4 신경망
__2.2.5 k-최근접 이웃
__2.2.6 결정 트리, 랜덤 포레스트, GBDT
2.3 회귀
__2.3.1 선형 회귀의 원리
2.4 군집화와 차원 축소
__2.4.1 군집화
__2.4.2 차원 축소
2.5 그 외
__2.5.1 추천
__2.5.2 이상 탐지
__2.5.3 패턴 마이닝
__2.5.4 강화 학습
2.6 정리
3장. 학습 결과 평가하기
3.1 분류 결과에 대한 평가 행렬
__3.1.1 그냥 정확도를 사용하면 될까?
__3.1.2 데이터 분포가 치우친 경우를 위한 지표 - 정밀도와 재현율
__3.1.3 균형 잡힌 성능을 평가하는 F-점수
__3.1.4 혼동행렬 따라잡기
__3.1.5 다중 클래스 분류의 평균 구하기 - 마이크로 평균과 매크로 평균
__3.1.6 분류 모델 비교하기
3.2 회귀 모델 평가하기
__3.2.1 평균제곱근오차
__3.2.2 결정 계수
3.3 머신러닝 시스템의 A/B 테스트
3.4 정리
4장. 기존 시스템에 머신러닝 통합하기
4.1 기존 시스템에 머신러닝을 통합하는 과정
4.2 시스템 설계
__4.2.1 헷갈리기 쉬운 ‘배치 처리’와 ‘배치 학습’
__4.2.2 배치 처리로 학습 + 예측 결과를 웹 애플리케이션에서 직접 산출(예측을 실시간 처리)
__4.2.3 배치 처리로 학습 + 예측 결과를 API를 통해 사용(예측을 실시간 처리)
__4.2.4 배치 처리로 학습 + 예측 결과를 DB에 저장하고 사용(예측을 배치 처리)
__4.2.5 실시간 처리로 학습
__4.2.6 각 패턴의 특성
4.3 로그 설계
__4.3.1 특징과 훈련 데이터에 사용되는 정보
__4.3.2 로그 저장하기
__4.3.3 로그 설계 시의 주의점
4.4 정리
5장. 학습 데이터 수집하기
5.1 학습 데이터를 얻는 방법
5.2 공개된 데이터셋이나 모델 활용
5.3 개발자가 직접 만드는 데이터셋
5.4 동료나 친구에게 데이터 입력을 부탁
5.5 크라우드소싱 활용
5.6 서비스에 수집 기능을 넣고 사용자가 입력하게 함
5.7 정리
6장. 효과 검증하기
6.1 효과 검증
__6.1.1 효과 검증까지 거쳐야 할 과정
__6.1.2 오프라인에서 검증하기 어려운 부분
6.2 가설 검정
__6.2.1 동전이 찌그러지진 않았을까
__6.2.2 두 그룹의 모비율의 차를 이용한 검정
__6.2.3 거짓 양성과 거짓 음성
6.3 가설 검정에서 주의할 점
__6.3.1 반복해서 검정하는 경우
__6.3.2 유의한 차이와 비즈니스 임팩트
__6.3.3 동시에 여러 가설 검정하기
6.4 인과효과 추정
__6.4.1 루빈 인과모형
__6.4.2 선택 편향
__6.4.3 무작위 대조시험
__6.4.4 과거와의 비교는 어렵다
6.5 A/B 테스트
__6.5.1 그룹 선정과 표본 크기
__6.5.2 A/A 테스트로 그룹의 균질성 확인
__6.5.3 A/B 테스트를 위한 구조 만들기
__6.5.4 테스트 종료
6.6 정리
2부. 머신러닝 실무 프로젝트
7장. 프로젝트 1: 영화 추천 시스템 만들기
7.1 시나리오
__7.1.1 추천 시스템이란
__7.1.2 응용 분야
7.2 추천 시스템 제대로 알기
__7.2.1 데이터 설계와 데이터 입수
__7.2.2 명시적 데이터와 묵시적 데이터
__7.2.3 추천 시스템의 알고리즘
__7.2.4 사용자 기반 협업 필터링
__7.2.5 아이템 기반 협업 필터링
__7.2.6 모델 기반 협업 필터링
__7.2.7 내용 기반 필터링
__7.2.8 협업 필터링과 내용 기반 필터링의 장단점
__7.2.9 평가 척도
7.3 무비렌즈 데이터 분석하기
7.4 추천 시스템 구현하기
__7.4.1 인수분해 머신을 이용한 추천
__7.4.2 인수분해 머신을 이용한 본격적인 학습
__7.4.3 사용자와 영화 외의 정보 추가하기
7.5 정리
8장. 프로젝트 2: 킥스타터 분석하기 - 머신러닝을 사용하지 않는 선택지
8.1 킥스타터 API 찾아보기
8.2 킥스타터 크롤러 만들기
8.3 JSON 데이터를 CSV로 변환하기
8.4 엑셀로 데이터 훑어보기
8.5 피벗 테이블로 데이터 분석하기
8.6 목표액 달성 후 취소된 프로젝트 살펴보기
8.7 국가별로 살펴보기
8.8 보고서 작성하기
8.9 이 다음에 할 일
8.10 정리
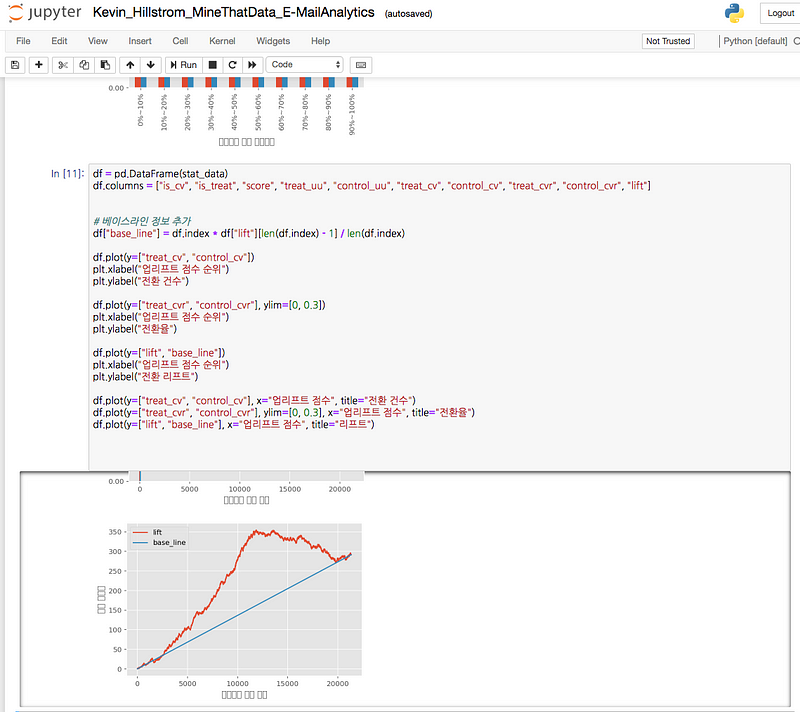
9장. 프로젝트 3: 업리프트 모델링으로 마케팅 효율 높이기
9.1 업리프트 모델링의 사분면
9.2 A/B 테스트를 확장한 업리프트 모델링
9.3 업리프트 모델링에 사용할 데이터셋 만들기
9.4 두 가지 예측 모델을 이용한 업리프트 모델링
9.5 AUUC로 업리프트 모델링 평가하기
9.6 실제 문제에 적용하기
9.7 업리프트 모델링을 서비스에 적용하기
9.8 정리
출판사리뷰
현업 개발자를 위한 색다른 머신러닝 실무서
머신러닝을 실제 시스템에 적용하려면 기존 이론서들에서는 다루지 않지만 꼭 필요한 지식이 적지 않다. 탐색적 분석에 대한 경험과 데이터 분석 업무를 수행하면서 경험적으로 익혀온 묵시적 지식 등이 여기 해당한다. 그래서 이 책은 머신러닝 프로젝트를 진행하는 과정을 따라 가며 실무자가 느낄 궁금증과 갈증을 해소해주도록 꾸몄다. 다른 입문서에서 다루는 머신러닝 알고리즘은 과감히 축약하고 노하우에 집중하여 얇고 경제적이다. 경험 많은 실무자라면 자신의 노하우와 비교, 정리하여 동료나 후임에게 전수해주는 모습도 아름다울 것이다.
머신러닝 알고리즘 입문서가 아닌 만큼, 머신러닝 초보자라면 다른 머신러닝 책으로 기초를 닦고 읽으면 저자들이 전하고자 하는 핵심이 더욱 잘 전달될 것이다.
추천사
“실제 머신러닝 시스템을 설계하는 방법을 폭넓게 설명하는 책이다. 7장 이후는 프로젝트를 통해 실제로 경험해보는 데 무게를 두고 있다. 머신러닝 기초를 익힌 후 읽으면 더 쉽게 이해될 것이다!”
_사이토, 아마존 독자



추천도서



오탈자 등록
