IT/모바일
지금까지는 하나의 CSV 파일을 처리하는 방법들을 살펴보았다. 예제들은 파이썬을 사용하여 프로그래밍을 통해서 파일을 처리하는 방법에 대한 아이디어를 제공해줬다. 파일이 하나뿐이라도 파일이 너무 커서 수동으로 처리할 수 없는 경우, 프로그래밍으로 처리하면 복사/붙여넣기 오류 및 오탈자 등 사람이 범하는 실수의 가능성이 줄어든다.
대부분의 경우에는 하나의 파일이 아닌 여러 개의 파일을 처리해야 하므로 수동으로 이를 처리하는 것은 비효율적이거나 불가능하다. 이러한 상황에서 파이썬은 데이터 처리를 자동화할 수 있으므로 데이터 분석의 범위를 확장할 수 있다. 이 절에서는 파이썬의 내장된 glob 모듈을 소개하고, 앞서 소개한 예제들을 토대로 여러 개의 CSV 파일을 처리하는 방법을 알아보겠다. 우선 여러 개의 CSV 파일을 처리하려면 여러 개의 CSV 파일을 만들어야 한다. 이번 예제에서는 세 개의 파일만 생성해서 사용할 것이다. 하지만 이 예제에서 소개되는 방법은 컴퓨터가 처리할 수 있는 수많은 파일로 확장할 수 있다.
| CSV 파일 # 1 |
1. 스프레드시트를 연다.
2. [그림 2-12]와 같이 데이터를 추가한다.
3. sales_january_2014.csv라는 이름으로 파일을 저장한다.
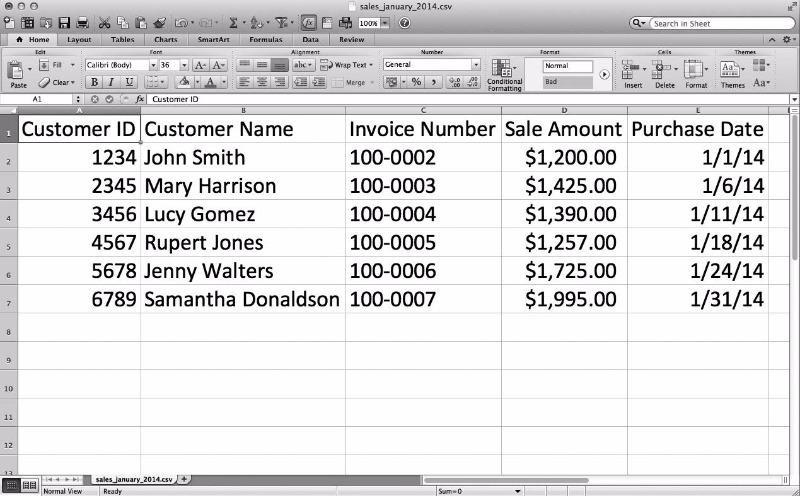
그림 2-12 CSV 파일 #1(sales_january_2014.csv)
| CSV 파일 # 2 |
1. 스프레드시트를 연다.
2. [그림 2-13]와 같이 데이터를 추가한다.
3. sales_february_2014.csv라는 이름으로 파일을 저장한다.
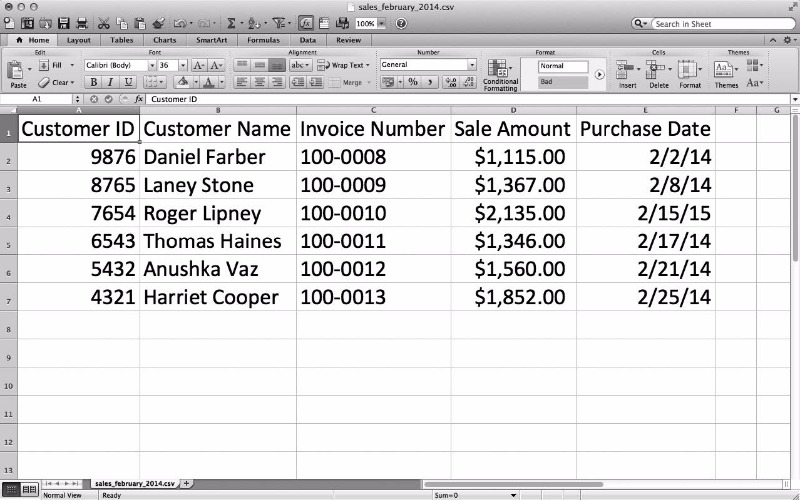
그림 2-13 CSV 파일 #2(sales_ february_2014.csv)
| CSV 파일 # 3 |
1. 스프레드시트를 연다.
2. [그림 2-14]와 같이 데이터를 추가한다.
3. sales_march_2014.csv라는 이름으로 파일을 저장한다.
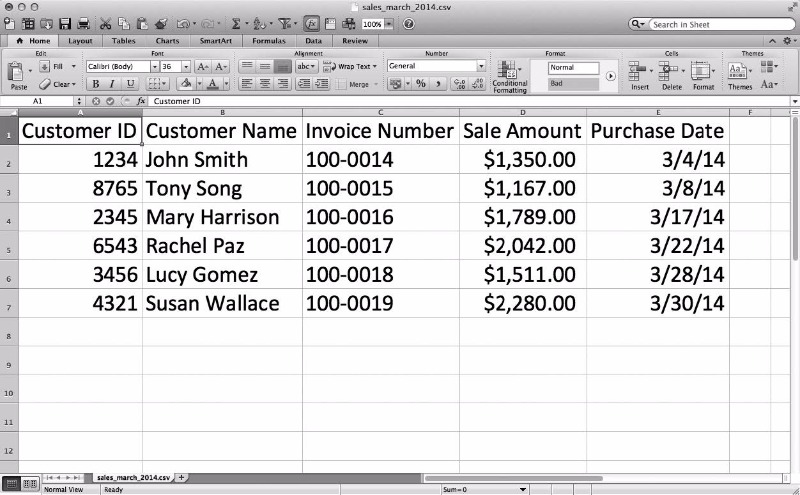
그림 2-14 CSV 파일 #3(sales_ march _2014.csv)
전체 파일 개수 및 각 파일의 행 및 열 개수 계산
행과 열의 개수를 세어보는 간단한 일부터 시작해보자. 이 작업은 매우 기본적이지만 새로운 데이터셋을 이해하는 좋은 방법이기도 하다. 경우에 따라서는 처리할 입력 파일의 내용을 미리 알 수도 있지만, 대부분의 경우 다른 사람에게 전달받은 일련의 파일을 처리해야 하므로 그 파일의 내용에 대해 곧바로 알기는 어렵다. 이런 경우 처리해야 하는 파일의 숫자를 확인하고, 각 파일의 행과 열의 개수를 계산해서 파악해두면 큰 도움이 된다.
위에서 작성한 세 개의 CSV 파일을 처리해보겠다. 텍스트 편집기에 다음 코드를 입력하고 파일명을 8csv_reader_counts_for_multiple_files.py로 저장한다.
#!/usr/bin/env python3
import csv
import glob
import os
import sys
input_path = sys.argv[1]
file_counter = 0
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
row_counter = 1
with open(input_file, 'r', newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
header = next(filereader)
for row in filereader:
row_counter += 1
print('{0!s}: \t{1:d} rows \t{2:d} columns'.format(\os.path.basename(input_file), row_counter, len(header)))
file_counter += 1
print('Number of files: {0:d}'.format(file_counter))
3행과 4행에서 파이썬에 내장된 glob과 os 모듈을 임포트했다. 이들 모듈의 함수를 사용하면 처리할 파일의 경로명을 나열하고 파싱할 수 있다. glob 모듈은 특정 패턴과 일치하는 모든 경로명을 찾는다. 패턴에는 * 등 유닉스 셸 스타일의 와일드카드 문자가 포함될 수 있다. 이 예제에서 찾으려는 패턴은 sales_*로서 sales_로 시작하는 이름을 가진 모든 파일을 찾는다. 밑줄 뒤에는 어떤 문자가 와도 상관이 없다. 앞서 세 개의 입력 파일을 만들 때 파일명을 모두 sales_로 시작한 다음 밑줄 뒤에는 다른 월 이름을 입력했으므로, 코드에서 이 패턴을 사용하여 세 개의 입력 파일을 식별할 수 있다.
뒤에서는 sales_로 시작하는 파일들이 아니라 폴더 속에 있는 모든 CSV 파일을 처리할 것인데, 그렇게 하려면 이 스크립트 속의 패턴을 sales_*에서 *.csv로 변경하기만 하면 된다. csv는 모든 CSV 파일의 이름 끝에 있는 패턴이므로 이 패턴을 통해서 모든 CSV 파일을 효과적으로 찾을 수 있다.
os 모듈은 경로명을 파싱하는 데 유용한 함수를 포함하고 있다. os.path.basename(path)은 입력받은 경로에서 파일명을 반환한다. 예를 들어 path가 "C:\Users\Clinton\Desktop\my_input_file.csv"라면 os.path.basename(path)는 y_input_file.csv를 반환한다.
10행은 여러 개의 입력 파일에서 데이터 처리를 위한 핵심이다. glob 및 os 모듈의 함수를 사용하여 처리할 입력 파일의 리스트를 만들어 for 문으로 일련의 입력 파일을 반복한다. 이 줄에는 많은 내용이 들어 있으므로 안쪽에서 바깥쪽으로 단계적으로 살펴보자. os 모듈의 os.path.join() 함수는 괄호 안에 있는 두 개의 컴포넌트를 결합한다. input_path는 입력 파일이 들어 있는 폴더의 경로이고 sales_*는 sales_ 패턴으로 시작하는 파일의 이름을 나타낸다.
glob 모듈의 glob.glob() 함수는 sales_*의 별표(*)를 실제 파일명으로 확장한다. 이 예제에서 glob.glob()과 os.path.join()은 세 개의 입력 파일이 들어 있는 리스트를 만든다.
['C:\Users\Clinton\Desktop\sales_january_2014.csv', 'C:\Users\Clinton\Desktop\sales_
february_2014.csv', 'C:\Users\Clinton\Desktop\sales_march_2014.csv']
그다음 줄 시작 부분의 for 문은 이 리스트에 포함된 각 입력 파일에 대해서 그 줄 아래 들여쓰기가 적용된 코드들을 실행한다.
17행은 각 입력 파일의 파일 이름, 파일의 행과 열의 수를 출력하는 print 문이다. print 문에 탭 문자(\t)가 반드시 필요한 것은 아니지만 열 사이에 탭을 넣으면 세 개의 열을 정렬하는데 도움이 된다. 이 행은 {} 문자를 사용하여 세 가지 값을 print 문에 전달한다. 첫 번째 값은 os.path.basename() 함수를 사용하여 전체 경로명의 마지막 요소를 추출한다. 두 번째 값은 row_counter 변수를 사용하여 각 입력 파일에서 행의 개수를 계산한다. 세 번째 값은 내장된 len() 함수를 사용하여, 각 입력 파일의 열 헤더가 들어 있는 리스트 변수 header에 들어 있는 원소의 개수를 계산한다. 이 값을 각 입력 파일이 갖는 열의 개수로 사용한다. 17행에서 각 파일에 대한 정보를 출력한 뒤, 마지막으로 20행은 file_counter의 값을 사용하여 스크립트에서 처리한 파일의 숫자를 출력한다.
스크립트를 실행하려면 명령 줄에 다음을 입력하고 엔터 키를 누른다.
python 8csv_reader_counts_for_multiple_files.py "C:\Users\Clinton\Desktop"
스크립트 파일 이름 뒤에 폴더 경로를 입력해야 한다. 이전 예제에서는 이곳에 입력 파일의 이름을 넣었다. 이번 예제는 다수의 입력 파일을 처리해야 하므로 모든 입력 파일이 들어 있는 폴더를 지정해야 한다.
스크립트가 실행되면 세 개의 입력 파일 이름과 각 파일의 행 및 열의 개수가 함께 화면에 출력된다. 세 개의 입력 파일에 대한 정보 밑에는 처리된 입력 파일의 총 개수가 표시된다. 화면에 출력된 정보는 [그림 2-15]와 같아야 한다.
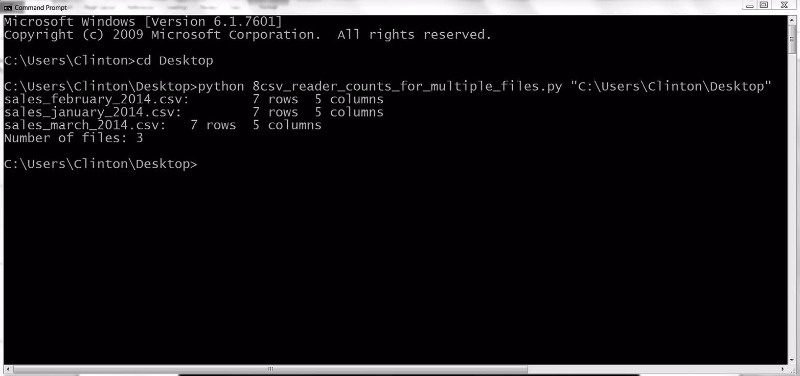
그림 2-15 파이썬 스크립트 실행 결과
스크립트가 3개의 파일을 처리했고, 각 파일에는 7개의 행과 5개의 열이 있음을 확인했다.
이번 예제로 여러 개의 CSV 파일을 읽고, 각 파일에 대한 기본 정보를 화면에 출력하는 방법을 살펴보았다. 처리할 입력 파일에 익숙하지 않다면 기본 정보를 출력해보는 것이 유용하다. 입력 파일의 개수와 각 파일의 행과 열의 수를 알면 처리해야 하는 작업의 규모를 예상할 수 있고 입력 파일의 형식적 일관성도 확인할 수 있다.
관련 콘텐츠








최신 콘텐츠