IT/모바일
데이터 과학의 파이프라인 및 워크플로우에는 복잡하고 반복적인 여러 단계가 포함되어 있습니다. 예를 들어, 가장 일반적인 머신러닝 모델은 데이터 준비 작업부터 시작하여 모델을 훈련하고 튜닝한 뒤, 훈련된 모델을 프로덕션 환경으로 배포합니다. 머신러닝 워크플로우 작업은 아래 그림처럼 복잡하고 반복적입니다.
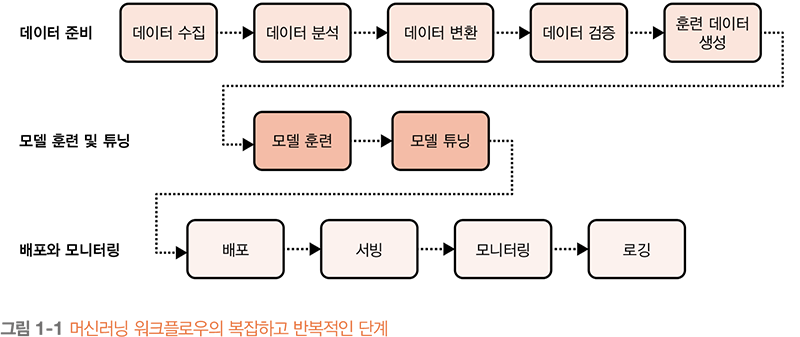
이때, 아마존 웹 서비스Amazon Web Services(AWS)를 사용하면 더욱 편리하게 데이터 과학 파이프라인 및 워크플로우의 여러 단계를 진행할 수 있습니다. 이번에는 파이프라인 및 워크플로우 구성에 활용할 수 있는 AWS 서비스를 알아보겠습니다.
데이터 준비
원시 데이터 저장: 아마존 심플 스토리지 서비스Amazon Simple Storage Service (아마존 S3)에 CSV, 아파치 파케이Apache Parquet 등의 형식으로 저장합니다. 원시 데이터 스토리지는 아마존 AI나 AutoML 같은 서비스를 이용해 모델 훈련 환경을 직접 연결시키고, 클릭 한 번만으로 모델 훈련을 빠르게 실행해 모델 성능의 기준 척도를 정할 수 있습니다.
커스텀 머신러닝 모델: 수동으로 데이터 분석, 데이터 품질 검사, 요약 통계, 결측값, 분위수 계산, 데이터 비대칭 분석, 상관 분석 등을 포함한 데이터 수집 및 탐색 단계를 시작할 수 있습니다.
훈련 데이터 생성하기: 사용자가 주어진 상황에 맞춰 가장 적합한 머신러닝 과제 타입 (회귀, 분류, 클러스터링)과 주어진 문제를 풀기에 가장 적합한 알고리즘을 선택합니다. 그 다음 알고리즘에 따라 데이터셋 일부를 취해 훈련, 검증 및 테스트용으로 나눕니다. 일반적으로 원시 데이터는 수치 최적화 및 모델 훈련이 가능하도록 수학적 벡터로 변환해야 합니다.
예를 들어, 범주형 컬럼을 원핫 인코딩된 벡터로 변환하거나 텍스트 형식의 컬럼들을 워드 임베딩 벡터로 변환합니다. 각 데이터 컬럼은 컬럼을 나타내는 특성을 반영해 이름을 짓거나 넘버링하여 피처feature라고 부르고, 데이터를 수학적 벡터로 변환하고 갈무리하는 작업 과정을 피처 엔지니어링feature engineering이라고 합니다. 피처 엔지니어링이 완료된 데이터셋을 이제 훈련용, 검증용, 테스트용 데이터셋으로 분할해 모델 훈련, 검증 및 테스트를 준비하면 됩니다.
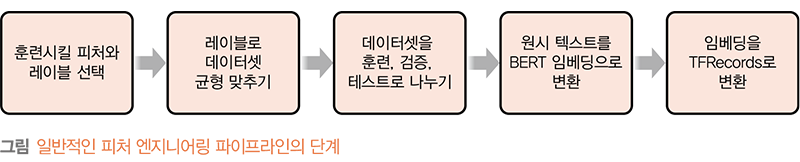
모델 훈련 및 튜닝
모델 훈련: 모델이 주어진 문제를 잘 해결할 수 있도록 알고리즘을 선택하고 훈련용, 검증용, 테스트용으로 분할한 데이터셋들 중 훈련용과 검증용 데이터셋을 이용해 모델을 훈련시킵니다.
모델 튜닝: 알고리즘의 하이퍼파라미터를 튜닝하고 검증 데이터셋에 대해 모델 성능을 평가합니다. 모델이 테스트 데이터셋에 대해 우리가 원하는 결과를 보여줄 때까지, 우리는 데이터 추가 혹은 하이퍼파라미터 바꾸기 등을 반복적으로 실험하고 실행하는 모델 튜닝 단계를 거쳐야 하죠. 이 모델 튜닝 결과는 모델을 프로덕션에 적용하기 전에 비즈니스 목표와 일치해야 합니다.
배포와 모니터링
프로토타입에서 프로덕션으로 이동하는 마지막 단계는 데이터 과학자와 머신러닝 실무자에게 가장 큰 과제입니다. 일반적인 머신러닝 파이프라인에서는 배포와 모니터링 작업을 위해 배포-서빙-모니터링-로깅 4단계를 거치게 됩니다.
머신러닝 워크플로우의 모든 단계를 빌드한 후 단계를 반복해서 단일 머신러닝의 파이프라인으로 자동화할 수 있습니다. 새 데이터가 S3에 도착하면 파이프라인이 최신 데이터로 다시 실행되고, 가장 최근 업데이트된 모델을 프로덕션으로 배포해 애플리케이션을 업데이트합니다. 사용자의 AutoML 파이프라인을 구축하는 데 이용 가능한 몇 가지 워크플로우 오케스트레이션 도구와 AWS 서비스를 살펴보겠습니다.
AI/ML 파이프라인을 아마존 세이지메이커에 구현하기 위한 가장 포괄적이고 기준이 되는 기능입니다. 세이지메이커 파이프라인들은 아래의 리스트와 통합되어 있습니다.
- 세이지메이커 피처 스토어 SageMaker Feature Store
- 세이지메이커 데이터 랭글러 SageMaker Data Wrangler
- 세이지메이커 프로세싱 SageMaker Processing
- 세이지메이커 트레이닝 SageMaker Training
- 세이지메이커 하이퍼파라미터 튜닝 SageMaker Hyperparameter Tuning
- 세이지메이커 모델 레지스트리 SageMaker Model Registry
- 세이지메이커 일괄 변환 SageMaker Batch Transform
- 세이지메이커 모델 엔드포인트 SageMaker Model Endpoint
② AWS 스텝 함수 데이터 과학AWS step function data science SDK
관리형 AWS 서비스인 스텝 함수는 자체 인프라를 빌드하거나 유지 관리하지 않고도 복잡한 워크플로우를 빌드할 수 있는 서버리스 형태의 서비스입니다. AWS 스텝 함수 데이터 과학 SDK를 사용해 세이지메이커 노트북과 같은 파이썬 환경에서 머신러닝 파이프라인을 빌드할 수 있습니다.
③ 큐브플로우 파이프라인Kubeflow pipeline
큐브플로우는 쿠버네티스 환경에 빌드된 큐브플로우 파이프라인이라는 오케스트레이션 하위 시스템을 포함하는 비교적 새로운 오픈 소스 머신러닝 플랫폼입니다. 큐브플로우를 사용하면 실패한 파이프라인을 다시 시작하고, 파이프라인 실행을 예약하고, 훈련 지표를 분석하고, 파이프라인 계보를 트래킹할 수 있습니다.
④ 아파치 에어플로우Apache Airflow를 위한 관리형 워크플로우
아파치 에어플로우는 주로 데이터 엔지니어링과 추출-변환-로드(ETL) 파이프라인을 조정하는 인기 있는 오픈 소스 워크플로우 플랫폼입니다. 아파치 에어플로우용 아마존 관리형 워크플로우Amazon Managed Workflow for Apache Airflow (아마존 MWAA)는 아파치 에어플로우를 사용해 작업의 방향성 비순환 그래프(DAG)로 워크플로우를 작성합니다. 에어플로우 스케줄러는 지정된 종속성을 따르며 작업자 배열 집합체에서 머신러닝 작업을 실행합니다. 에어플로우 사용자 인터페이스를 통해 프로덕션에서 실행 중인 파이프라인을 시각화하고 진행 상황을 모니터링하여 문제를 해결할 수 있습니다.
⑤ MLflow
MLflow는 처음에 모델의 실험을 트래킹하는 데 중점을 둔 라이브러리였지만, 현재는 MLflow 워크플로우MLflow Workflow라는 파이프라인을 지원하는 오픈 소스 ML 플랫폼입니다. MLflow를 사용해 큐브플로우와 아파치 에어플로우 워크플로우의 실험을 트래킹할 수도 있습니다. 다만 MLflow는 우리가 직접 자체 아마존 EC2 또는 아마존 EKS 클러스터를 빌드하고 유지 관리해야 하는 특징이 있습니다.
⑥ 텐서플로우 익스텐디드TensorFlow Extended (TFX)
텐서플로우 익스텐디드는 AWS 스텝 함수, 큐브플로우 파이프라인, 아파치 에어플로우, MLflow와 같은 파이프라인 오케스트레이터에서 사용하는 파이썬 라이브러리들의 오픈 소스 컬렉션입니다. 텐서플로우 익스텐디드는 텐서플로우에만 해당되며 싱글 프로세싱 노드 그 이상을 넘어서 확장하기 위해서는 그 밖의 파이프라인 모델로 구성된 오픈 소스 프로젝트인 아파치 빔Apache Beam에 의존해야 합니다.
⑦ 휴먼인더루프 워크플로우
인공지능과 머신러닝 서비스가 우리의 삶을 더 편하게 만들어준다고 해서 인간이 필요 없는 존재가 되는 건 결코 아닙니다. 실제로, 휴먼인더루프human in the loop라는 용어는 AI/ML 워크플로우에서 중요한 초석으로 부상했습니다. 프로덕션 환경에서 제공되는 모델이 민감하고 규제의 영역에 있는 경우 인간은 중요한 품질 검증을 제공할 수 있죠.
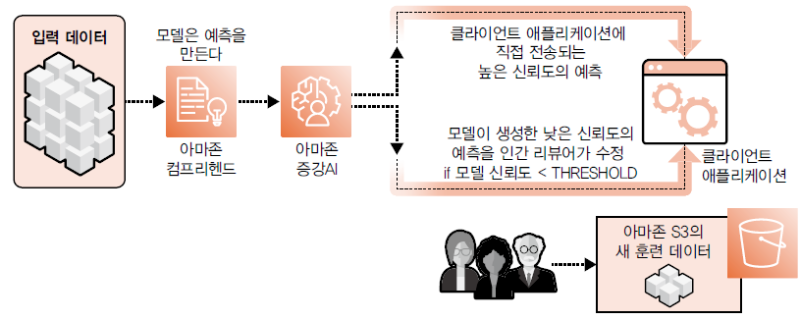
모델 예측을 검토하기 위한 아마존 증강 AI 워크플로우
아마존 증강 AI Amazon Augmented AI(아마존 A2I)는 UI, AWS 자격 증명 및 액세스 관리Identity and access management (IAM)를 사용한 역할 기반 액세스 제어, S3를 사용한 확장 가능한 데이터 스토리지를 포함하는 휴먼인더루프 워크플로우를 개발하기 위한 완전 관리형 서비스입니다. 또한 아마존 증강 AI는 사진이나 비디오 같은 콘텐츠 심의 규제를 위한 아마존 레코그니션Amazon Rekognition과 폼form 형태의 데이터 추출을 위한 아마존 텍스트랙트Amazon Textract를 포함한 많은 아마존 AI 서비스와 통합됩니다. 또한 우리는 아마존 A2I를 아마존 세이지메이커와 커스텀 머신러닝 모델과 함께 사용할 수 있죠.
아마존 세이지메이커를 사용한 아마존 AI와 AutoML
데이터 과학 프로젝트는 복잡하면서 다양한 분야와 반복적인 단계를 통해 진행됩니다. 우리는 머신러닝 모델의 프로토타입 단계를 지원하고, 프로덕션 서비스에 모델을 원활하게 배포할 수 있는 머신러닝 개발 환경에 액세스가 필요합니다. 또한 다양한 기계 학습 프레임워크와 알고리즘을 실험하고, 커스텀 모델 훈련 과 추론 코드를 개발하고자 하죠.
다른 경우에는, 쉽게 사용할 수 있고 사전 훈련된 모델을 이용해 간단히 작업을 해결하거나 AutoML 기술을 활용해 프로젝트의 첫 베이스라인을 만들고자 할 수도 있습니다.
AWS는 데이터 과학 프로젝트 진행 시 발생할 수 있는 다양한 시나리오에 적용할 수 있는 광범위한 서비스와 기능을 제공합니다. 아래 그림은 AI 서비스와 AutoML용 아마존 세이지메이커 오토파일럿을 포함한 전체 아마존 AI와 ML 스택을 보여줍니다.
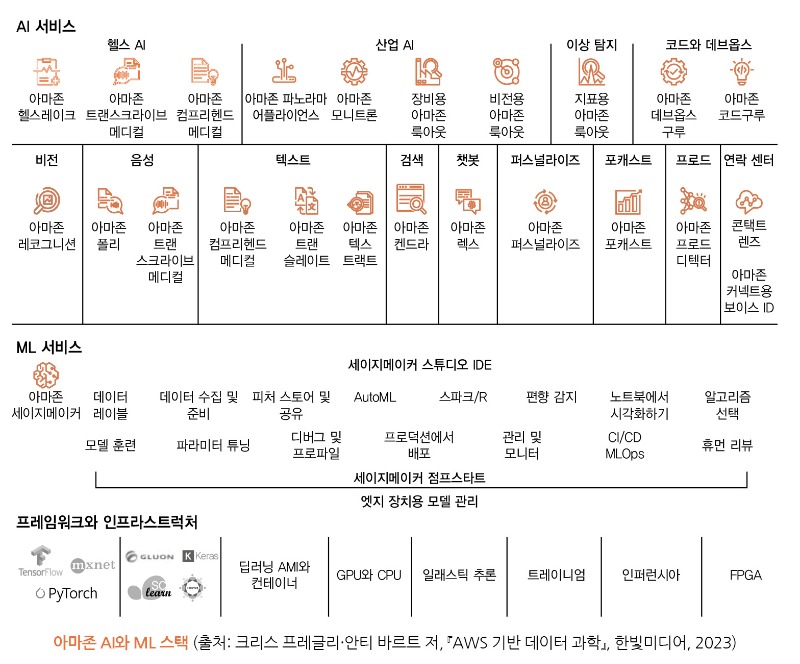
이 글은 도서 <AWS 기반 데이터 과학> 내용 중 일부를 편집하여 작성되었습니다. 머신러닝을 엣지에 도입하든, 인공지능과 머신러닝 여정의 시작 단계에 있든, 컴퓨터 비전·강화 학습·적대적 생성 네트워크(GAN)를 시작할 수 있는 재미있는 교육 방법을 찾고 있든지 간에 우리는 바로 사용할 수 있는 AI 서비스로 우리의 애플리케이션을 풍부하게 만들 수 있습니다.
아마존 클라우드 분야 베스트셀러! AWS를 기반으로 데이터 과학 프로젝트를 진행하는 모든 이를 위한 <AWS 기반 데이터 과학>에서 더 많은 정보를 확인해 보세요.


최신 콘텐츠